问题 先来看一段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <iostream>
#include <algorithm>
using namespace std ;
#define ARRAY_SIZE(array) sizeof(array) / sizeof(array[0])
int main ()
{
int nums [] = { 1 , 2 , 3 , 4 };
auto print_nums = [] ( auto & n ) {
cout << n << endl ;
};
auto process_nums = [] ( auto & n ) {
//do more process here
n *= n ;
};
for_each ( nums , nums + ARRAY_SIZE ( nums ), process_nums );
for_each ( nums , nums + ARRAY_SIZE ( nums ), print_nums );
}
我们有一个数组, 对其进行了某种操作process_nums之后, 打印print_nums出数组的值;
接下来, 假设我们发现, 使用数组来表示这段数据已经不符合项目要求了, 打算将数组换成list, 代码应该怎么改呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main ()
{
// int nums[] = {1, 2, 3, 4};
list < int > nums { 1 , 2 , 3 , 4 };
auto print_nums = [] ( auto & n ) {
cout << n << endl ;
};
auto process_nums = [] ( auto & n ) {
//do more process here
n *= n ;
};
// for_each(nums, nums + ARRAY_SIZE(nums), process_nums);
// for_each(nums, nums + ARRAY_SIZE(nums), print_nums);
for_each ( nums . begin (), nums . end (), process_nums );
for_each ( nums . begin (), nums . end (), print_nums );
}
可以看到, 不仅原始数据结构要改(int[]改为list<int>), 对这些数据调用的部分(两个for_each)也需要改.
按照这种情况, 如果是设计算法, 就需要根据不同数据的访问方法实现不同的接口.
迭代器 所幸, 所有的STL容器有考虑到这一点, 无论何种容器, 都应该有统一的接口给算法调用, 这样算法就可以处理所有容器的数据.
这就是迭代器.
迭代器可以隔离容器的底层实现, 调用容器数据只需依赖迭代器的统一接口.
再看一个例子, 使用通用迭代器和不使用通用迭代器的区别, 将上文的代码改造一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main ()
{
int nums [] = { 1 , 2 , 3 , 4 };
// list<int> nums{1, 2, 3, 4};
auto print_nums = [] ( auto & n ) {
cout << n << endl ;
};
auto process_nums = [] ( auto & n ) {
//do more process here
n *= n ;
};
using std :: begin ;
using std :: end ;
for_each ( begin ( nums ), end ( nums ), process_nums );
for_each ( begin ( nums ), end ( nums ), print_nums );
}
我们使用迭代器, 无论是普通数组还是容器(容器已经有通用的接口了), 都可以使用相同的接口访问其数据.
begin: returns an iterator to the beginning of a container or array
end: returns an iterator to the end of a container or array
begin和end 除了我们认知的容器中的C.begin()和C.end()的方法, C++也给我们提供了函数模板, 可以获取容器和数组的迭代器. (上文中的begin和end).
先来看看begin的定义, end类似:
1
2
3
4
5
6
template < class Container >
auto begin ( Container & cont ) -> decltype ( cont . begin ());
template < class Container >
auto begin ( const Container & cont ) -> decltype ( cont . begin ());
template < class T , size_t N >
T * begin ( T ( & arr )[ N ]);
对容器, begin返回的是容器的begin()方法的返回值; 对数组, begin返回的是指针. 在上文和之前的文章中已经用到过begin和end了, 这里就不在介绍用法.
当然, 可以返回迭代器的不只有begin和end .
我们注意到begin可以返回指针, 所以对下面这种情况也没有什么意外的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main ()
{
using std :: begin ;
using std :: end ;
{
int nums [] = { 1 , 2 , 3 };
auto it = begin ( nums );
cout << typeid ( it ). name () << endl ;
}
cout << "--------------" << endl ;
{
vector < int > nums { 1 , 2 , 3 };
auto it = begin ( nums );
cout << typeid ( it ). name () << endl ;
}
return 1 ;
}
输出是:
1
2
3
Pi
--------------
N9__gnu_cxx17__normal_iteratorIPiSt6vectorIiSaIiEEEE
第一个it是指针类型(指针), 第二个it是iterator类型(类).
指针和迭代器是一回事吗?
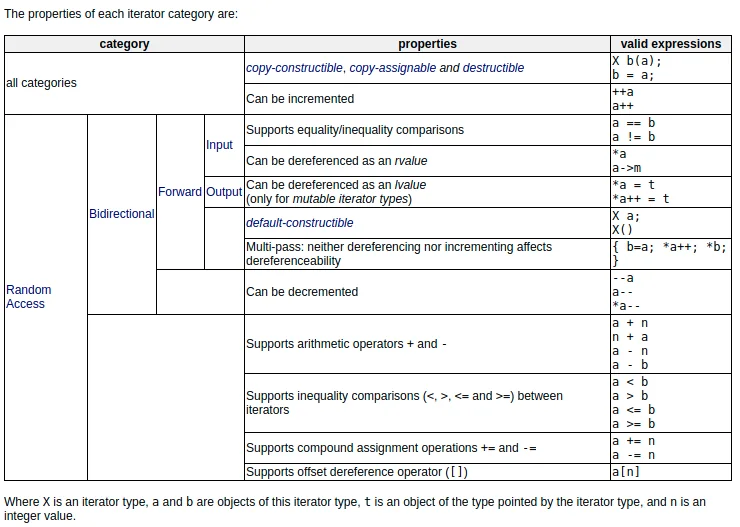
迭代器的分类 迭代器的分类(来自http://www.cplusplus.com/reference/iterator/)
按照cplusplus 给出分类, 迭代器分为以下几种:
对所有的迭代器, 均支持拷贝构造和复制操作, 均可执行自加操作(++a和a++); 对input迭代器, 支持等于或不等于判断, 支持解引用操作; 对output迭代器, 可被解引用并且被赋值(解引用后可以作为左值); 对forward迭代器, 支持input和output的所有特性, 目前所有的标准容器至少支持forward迭代器 ; 对bidirectional迭代器, 支持forward迭代器的所有特性, 同时可以自减, 相当于可以双向访问; 对random access迭代器, 支持bidirectional迭代器的所有特性, 同时可以使用迭代器+偏置的方法访问所有元素, 也支持迭代器的大小比较, 可以使用下标访问; 指针满足random access迭代器的所有特性. 所以, 指针是random access迭代器.
自定义迭代器 1
2
3
4
5
6
7
8
9
template < class Category , class T , class Distance = ptrdiff_t ,
class Pointer = T * , class Reference = T &>
struct iterator {
typedef T value_type ;
typedef Distance difference_type ;
typedef Pointer pointer ;
typedef Reference reference ;
typedef Category iterator_category ;
};
上述代码是C++提供的迭代器的基类, 但是没有提供任何方法, 只是定义了一些成员类型.
value_type指代元素类型difference_type指代两个元素距离的数据类型pointer指代元素指针形式的类型reference指代元素引用形式的类型iterator_category指代迭代器所属的迭代器类型(上文中的五类类型)前四种类型还好理解, iterator_category指代迭代器类型我认为是用来限制迭代器权限的. 我们来看下面的一段改编的例子 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// std::iterator example
#include <iostream> // std::cout
#include <iterator> // std::iterator, std::input_iterator_tag
#include <algorithm> // for_each
class MyIterator : public std :: iterator < std :: input_iterator_tag , int >
{
int * p ;
public :
MyIterator ( int * x ) : p ( x ) {}
MyIterator ( const MyIterator & mit ) : p ( mit . p ) {}
MyIterator & operator ++ () { ++ p ; return * this ;}
MyIterator operator ++ ( int ) { MyIterator tmp ( * this ); operator ++ (); return tmp ;}
bool operator == ( const MyIterator & rhs ) const { return p == rhs . p ;}
bool operator != ( const MyIterator & rhs ) const { return p != rhs . p ;}
int & operator * () { return * p ;}
};
int main () {
int numbers [] = { 10 , 20 , 30 , 40 , 50 };
MyIterator begin ( numbers );
MyIterator end ( numbers + 5 );
for_each ( begin , end , []( const int & n ){
std :: cout << n << ' ' ;
});
std :: cout << '\n' ;
return 0 ;
}
这里自定义了迭代器MyIterator. 通过iterator基类可以知道, 这是一个input迭代器, 元素是int型的.
接下来需要按照input迭代器的权限去实现不同的方法, 需要支持: 拷贝构造/自加/等于或不等于判断/解引用.
iterator_traits iterator基类的成员类型在使用trait的时候很有用, C++也为迭代器提供了trait模板iterator_traits.
根据trait模板, 我们可以提取上述迭代器定义的成员类型. 下面又是一段官方例子 :
1
2
3
4
5
6
7
8
9
10
11
// iterator_traits example
#include <iostream> // std::cout
#include <iterator> // std::iterator_traits
#include <typeinfo> // typeid
int main () {
typedef std :: iterator_traits < int *> traits ;
if ( typeid ( traits :: iterator_category ) == typeid ( std :: random_access_iterator_tag ))
std :: cout << "int* is a random-access iterator" ;
return 0 ;
}
输出是:
1
int* is a random-access iterator
同上文结论一样, 指针是random access迭代器.
小结 这篇文章的目的是理解什么是迭代器, 而不是知道这样用就行了(这也是我此前对迭代器的疑惑). 综上所述, 我们对迭代器的认知可以有以下结论:
迭代器是访问数组或容器数据的一种方式; 迭代器的目的是为数组或容器数据提供统一的访问接口; 指针也是迭代器, 但是不怎么通用; 在强调一点我认为比较重要的, 迭代器是访问数组或容器数据的方式, 而不是访问任何数据的方式, 这里要和指针区分的.