我们经常可以看到, 诸如Chrome/VSCode之类的程序打开运行的时候, 可以在后台看到会有多个相关进程启动. 同一个程序启动的不同进程间, 必然存在合作关系, 那么这些进程之间是如何合作的呢?
IPC 进程间通信也叫做IPC(InterPorcess Communication). 进程间通信可以让不同的进程共同合作完成某些任务.
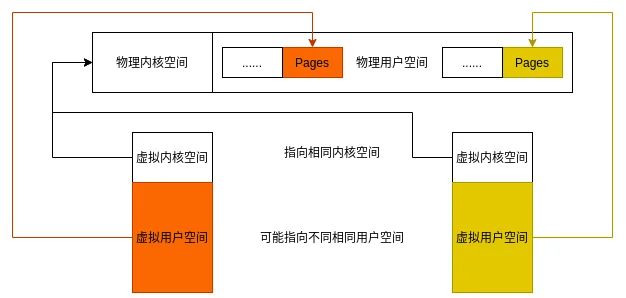
不同进程的虚拟内存空间可能会映射到不同的物理内存空间, 但是虚拟内存空间中的虚拟内核空间都会映射到相同的物理内核空间, 因为一般认为系统的内核只有一个.
不同进程映射到相同物理内核空间
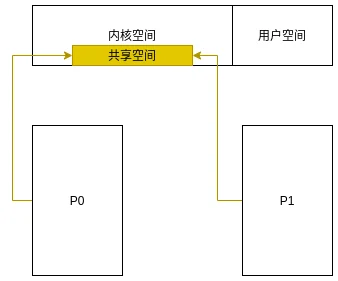
所以, 为了剔除用户空间映射不一致的影响, 可以在内核空间操作, 只要在内核空间中开辟相同的物理内存, 供不同进程访问, 那么就可以做到IPC.
内核提供共享区域做IPC
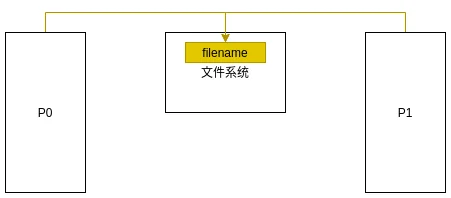
或者, 可以使用文件做IPC. 不同进程只要能够指向相同的文件, 再加上对文件的访问控制, 就可以在不同进程间通过文件系统通信.
使用文件系统做IPC
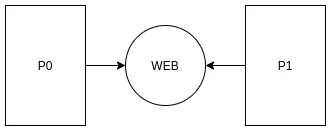
再或者, 可以通过我们熟知的网络链接做IPC.
通过网络做IPC
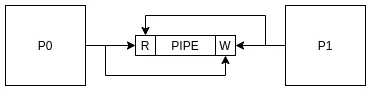
匿名管道 C提供了pipe函数用于创建管道. pipe是内核在内核空间提供的一段缓存区.
pipe 1
2
3
4
5
/* Create a one-way communication channel (pipe).
If successful, two file descriptors are stored in PIPEDES;
bytes written on PIPEDES[1] can be read from PIPEDES[0].
Returns 0 if successful, -1 if not. */
extern int pipe ( int __pipedes [ 2 ]) __THROW __wur ;
pipe输入参数是包含两个pipe描述符的二元数组. pipe执行失败返回-1, 执行成功则返回0, 同时第一个pipe描述符PIPEDES[0]指向pipe的读端, 第二个pipe描述符PIPEDES[1]指向pipe的写端. 调用pipe之后我们拿到了读写端口, 然后再调用fork函数, 现在父子进程都拿到了pipe的读写端口.
父子进程都拿到了pipe的读写端口
Create a one-way communication channel (pipe).
函数注释中已经说明, pipe是一个one-way communication channel, 只能一个通路, 也就是说只能从一端进一端出, 所以在父子进程必须确定谁来发送, 谁来接收, 不用的端口需要关闭.
下面的例子使用子进程写, 父进程读:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
int main ()
{
int pipef [ 2 ] = { 0 , 0 };
int ret = pipe ( pipef );
if ( ret < 0 )
{
printf ( "create pipe error \n " );
return - 1 ;
}
printf ( "pipef[0] %d, pipef[1] %d \n " , pipef [ 0 ], pipef [ 1 ]);
int pid = fork ();
if ( pid < 0 )
{
printf ( "fork error \n " );
return - 1 ;
}
else if ( pid == 0 )
{
//close read
close ( pipef [ 0 ]);
char msg [ 128 ] = "pipe message." ;
int count = 5 ;
while ( count -- > 0 )
{
strcat ( msg , "+" );
int write_stat = write ( pipef [ 1 ], msg , sizeof ( msg ));
printf ( "child send[%d]: %s \n " , write_stat , msg );
// sleep(1);
}
printf ( "write complete \n " );
close ( pipef [ 1 ]);
}
else
{
//close write
close ( pipef [ 1 ]);
char msg [ 1024 ] = { 0 };
int count = 5 ;
while ( count -- > 0 )
{
int read_stat = read ( pipef [ 0 ], msg , sizeof ( msg ));
if ( read_stat > 0 )
{
printf ( "parent get[%d]: " , read_stat );
for ( int i = 0 ; i < read_stat ; i ++ )
{
printf ( "%c" , msg [ i ]);
}
printf ( " \n " );
}
}
printf ( "read complete \n " );
close ( pipef [ 0 ]);
}
}
运行这段代码, 得到输出:
1
2
3
4
5
6
7
8
9
pipef[0] 6, pipef[1] 7
child send[128]: pipe message.+
child send[128]: pipe message.++
child send[128]: pipe message.+++
child send[128]: pipe message.++++
child send[128]: pipe message.+++++
write complete
parent get[640]: pipe message.+pipe message.++pipe message.+++pipe message.++++pipe message.+++++
read complete
并不符合预期, 子进程已经成功发送了五条信息, 但是父进程一口气全部读出来了, 为什么呢? 实际上这段程序每次执行的结果可能都不同. 这是因为pipe被设计为了循环队列, write负责从一端写, read负责从一端读. 上述问题在与, 还没开始读的时候, 写操作就完成了, 所以读的时候会将所有的数据读出(读的大小设置的1024B, 大于5次写128B共计640B). 所以, 将每次read的size改为每次写的size(=128), 就可以正常读出数据了:
1
2
3
4
5
6
7
8
9
10
11
12
13
pipef[0] 6, pipef[1] 7
parent get[128]: pipe message.+
child send[128]: pipe message.+
child send[128]: pipe message.++
child send[128]: pipe message.+++
parent get[128]: pipe message.++
child send[128]: pipe message.++++
child send[128]: pipe message.+++++
parent get[128]: pipe message.+++
write complete
parent get[128]: pipe message.++++
parent get[128]: pipe message.+++++
read complete
所有数据都正常写入和读出, 并且可见是异步的, 符合预期.
从上述信息中我们可以看到, 要使用pipe最好要在读写端约定写入的大小, 以保证可以按此大小读取. 一般来说, pipe读写可能会遇到四个问题:
读端和写端都是打开的, 但是还没有读, 这时候写端正常, 直到pipe被写满, 这会阻塞, 直到read将pipe里面的数据读出, pipe有空闲位置; 读端和写端都是打开的, 但是还没有写, 这时候如果pipe中有数据, 这正常读, 如果没有数据, 则阻塞, 直到往pipe里写入数据; 读端打开, 写端关闭, 这时候读端正常工作, 不阻塞, read返回值标识读到的数据大小, 为0则标识没有数据了; 读端关闭, 写端打开, 这时候会触发SIGPIPE信号, 此时往往是异常状态; pipe全双工 使用两个pipe可以实现全双工通信.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
int main ()
{
int pipef [ 2 ] = { 0 , 0 };
int pipes [ 2 ] = { 0 , 0 };
int ret = pipe ( pipef );
if ( ret < 0 )
{
printf ( "create pipe error \n " );
return - 1 ;
}
ret = pipe ( pipes );
if ( ret < 0 )
{
printf ( "create pipe error \n " );
return - 1 ;
}
printf ( "pipef[0] %d, pipef[1] %d \n " , pipef [ 0 ], pipef [ 1 ]);
printf ( "pipes[0] %d, pipes[1] %d \n " , pipes [ 0 ], pipes [ 1 ]);
int pid = fork ();
if ( pid < 0 )
{
printf ( "fork error \n " );
return - 1 ;
}
else if ( pid == 0 )
{
//close read
close ( pipef [ 0 ]);
//close write
close ( pipes [ 1 ]);
char msg [ 128 ] = "child message." ;
int count = 5 ;
while ( count -- > 0 )
{
strcat ( msg , "+" );
int write_stat = write ( pipef [ 1 ], msg , sizeof ( msg ));
printf ( "child send[%d]: %s \n " , write_stat , msg );
char read_msg [ 1024 ] = { 0 };
int read_stat = read ( pipes [ 0 ], read_msg , sizeof ( read_msg ));
if ( read_stat > 0 )
{
printf ( "get from parent: %s \n " , read_msg );
}
}
printf ( "child complete \n " );
close ( pipef [ 1 ]);
close ( pipes [ 0 ]);
}
else
{
//close write
close ( pipef [ 1 ]);
//close read
close ( pipes [ 0 ]);
char msg [ 128 ] = "parent message." ;
int count = 5 ;
while ( count -- > 0 )
{
strcat ( msg , "+" );
int write_stat = write ( pipes [ 1 ], msg , sizeof ( msg ));
printf ( "parent send[%d]: %s \n " , write_stat , msg );
char read_msg [ 1024 ] = { 0 };
int read_stat = read ( pipef [ 0 ], read_msg , sizeof ( read_msg ));
if ( read_stat > 0 )
{
printf ( "get from child: %s \n " , msg );
}
}
printf ( "parent complete \n " );
close ( pipef [ 0 ]);
close ( pipes [ 1 ]);
}
}
输出可能是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
pipef[0] 6, pipef[1] 7
pipes[0] 8, pipes[1] 9
parent send[128]: parent message.+
child send[128]: child message.+
get from parent: parent message.+
child send[128]: child message.++
get from child: parent message.+
parent send[128]: parent message.++
get from parent: parent message.++
child send[128]: child message.+++
get from child: parent message.++
parent send[128]: parent message.+++
get from parent: parent message.+++
child send[128]: child message.++++
get from child: parent message.+++
parent send[128]: parent message.++++
get from parent: parent message.++++
child send[128]: child message.+++++
get from child: parent message.++++
parent send[128]: parent message.+++++
get from parent: parent message.+++++
child complete
parent complete
可以看到, 读取的时候并没有和写入端约定大小, 但是这时候是可以正常读的, 为什么呢? 分析一下代码可能的逻辑:
子进程先走, 正常write, read的时候, pipe中没有数据, 则阻塞; 父进程走, 正常write, 子进程的read读到了数据, 退出阻塞, 父进程可以正常读到子进程write的数据; 父进程先走, 正常write, read的时候, pipe中没有数据, 则阻塞; 子进程走, 正常write, 父进程的read读到了数据, 退出阻塞, 子进程可以正常读到父进程write的数据;
所以, 无论父子进程怎么走, 都可以保证父子进程的正常读写. pipe的容量和原子性 上面的例子都没有填满pipe, 也都默认了pipe的读写都是原子的. 到这里又想到了两个问题:
pipe什么时候写满? pipe读写怎么保证是原子操作(读写一致性)? 使用man查看pipe的描述:
关于pipe容量的.
Pipe capacity
In Linux versions before 2.6.11, the capacity of a pipe was the same as the system page size (e.g., 4096 bytes on i386). Since Linux 2.6.11, the pipe capacity is 16 pages (i.e., 65,536 bytes in a system with a page size of 4096 bytes). Since Linux 2.6.35, the default pipe capacity is 16 pages, but the capacity can be queried and set using the fcntl(2) F_GETPIPE_SZ and F_SETPIPE_SZ operations. See fcntl(2) for more information.
pipe容量在不同的linux版本中不同, 从Linux 2.6.11开始是16Pages, 所以是$4096 Bytes \times 16 Pages = 65535 Bytes$.
关于pipe如何保证一致性的.
PIPE_BUF
POSIX.1 says that write(2)s of less than PIPE_BUF bytes must be atomic: the output data is written to the pipe as a contiguous sequence. Writes of more than PIPE_BUF bytes may be nonatomic: the kernel may interleave the data with data written by other processes. POSIX.1 requires PIPE_BUF to be at least 512 bytes. (On Linux, PIPE_BUF is 4096 bytes.)
当写入的字节流大小不大PIPE_BUF时, pipe可以保证写入的原子性(读写一致性), 如果写入字节流大于PIPE_BUF则无法保证写入的原子性. PIPE_BUF至少时512Bytes, 在Linux上PIPE_BUF时$4096Bytes = 1Page$.
pipe源码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/*
* sys_pipe() is the normal C calling standard for creating
* a pipe. It's not the way Unix traditionally does this, though.
*/
static int do_pipe2 ( int __user * fildes , int flags )
{
struct file * files [ 2 ];
int fd [ 2 ];
int error ;
error = __do_pipe_flags ( fd , files , flags );
if ( ! error ) {
if ( unlikely ( copy_to_user ( fildes , fd , sizeof ( fd )))) {
fput ( files [ 0 ]);
fput ( files [ 1 ]);
put_unused_fd ( fd [ 0 ]);
put_unused_fd ( fd [ 1 ]);
error = - EFAULT ;
} else {
fd_install ( fd [ 0 ], files [ 0 ]);
fd_install ( fd [ 1 ], files [ 1 ]);
}
}
return error ;
}
基本可以看出来pipe涉及到了文件操作struct file *files[2];, pipe和pipe2函数是对do_pipe2的封装.
匿名管道不属于任何文件系统,只存在于内存中,它是无名无形的,但是可以把它看作一种特殊的文件,通过使用普通文件的read(), write()函数对管道进行操作.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static int __do_pipe_flags ( int * fd , struct file ** files , int flags )
{
int error ;
int fdw , fdr ;
if ( flags & ~ ( O_CLOEXEC | O_NONBLOCK | O_DIRECT ))
return - EINVAL ;
error = create_pipe_files ( files , flags );
if ( error )
return error ;
error = get_unused_fd_flags ( flags );
if ( error < 0 )
goto err_read_pipe ;
fdr = error ;
error = get_unused_fd_flags ( flags );
if ( error < 0 )
goto err_fdr ;
fdw = error ;
audit_fd_pair ( fdr , fdw );
fd [ 0 ] = fdr ;
fd [ 1 ] = fdw ;
return 0 ;
err_fdr :
put_unused_fd ( fdr );
err_read_pipe :
fput ( files [ 0 ]);
fput ( files [ 1 ]);
return error ;
}
创建pipe的时候会查找可用fd, 如果fd不够了, 则会创建pipe失败. 在日常开发中, fd如果没有正常释放, 则可能会导致fd不够.
小结 综上所述:
pipe是半双工; 两个pipe可以实现全双工; pipe只能在具有亲缘关系的进程间通信; 读写端都存在时, pipe满则阻塞写端, pipe空则阻塞读端; 读端不存在, 则写时触发SIGPIPE信号, 写端不存在时, 读正常, 但是不阻塞; pipe传输的是字节流; pipe的最大容量一般是64Pages, 写入小于1Page的字节流可以保证读写一致性; Linux系统中的命令, 如ls | grep txt中的|就是匿名管道, 实现两个进程中的通信. 具名管道 上述讲了匿名管道, 没有一个标识符(名字)指向的管道, 所以一般只能用在亲缘进程中(创建时共享了内存). 试想, 如果给管道加上了名字, 是不是就可以在不同的进程间通信了呢? 这就是具名管道.
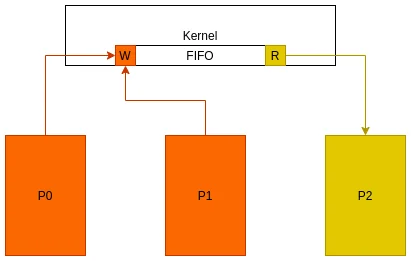
具名管道可以认为是pipe加上了名字. Linux中将这种具名管道叫做fifo.
fifo和pipe类似, 但是可以在文件系统中找到fifo的管道文件, fifo文件是存在系统中的文件. 进程可以根据fifo的名字打开fifo, 并对其读写, 但是进程会将fifo的数据缓存在内核中(类比pipe), 并不会将数据写入文件, 所以在fifo文件中也无法找到对fifo写入的数据.
我们可以使用ls -lh命令, 看到系统中的fifo文件, 如:
1
prwxrwxr-x 1 ** ** 0 4月 25 17:37 ./fifo_pipe
权限一栏的p就标识这是一个pipe(管道, 要和上述的pipe函数区分一下)文件.
如果ll看的话, 会有类似以下输出:
1
2
3
4
5
prwxrwxr-x 1 ** ** 0 4月 25 17:37 fifo_pipe|
-rwxrwxr-x 1 ** ** 8616 4月 25 17:17 fifo_read*
-rw-rw-r-- 1 ** ** 704 4月 25 17:42 fifo_read.c
-rwxrwxr-x 1 ** ** 8744 4月 25 17:18 fifo_write*
-rw-rw-r-- 1 ** ** 1630 4月 25 17:35 fifo_write.c
fifo_pipe作为一个管道文件, 会有p字符标识, 文件名后也有|标识.
同pipe, fifo也可以使用open, write等IO接口函数对其操作.
人如其名, fifo的结构如下, 是内核中的一个先进先出的队列, 比如只能在尾部写入, 那么就只能在头部读出, 所以, 如果对应多个进程读写时, 就要约定写入的size和标识符规则.FIFO管道结构
关于fifo跟官方的内容可以:
C提供了mkfifo函数用于创建fifo(创建, 不是打开).
mkfifo mkfifo需要传入fifo的路径和fifo打开模式.
1
2
3
/* Create a new FIFO named PATH, with permission bits MODE. */
extern int mkfifo ( const char * __path , __mode_t __mode )
__THROW __nonnull (( 1 ));
如果fifo文件路径已经存在, 则mkfifo会报错, 如果fifo文件不存在, 则mkfifo会根据fifo路径创建fifo文件. 所以在调用mkfifo的时候, 需要判断fifo路径是否已经存在:
1
2
3
4
5
6
7
8
9
10
if ( access ( fifo_name , F_OK ) == - 1 )
{
printf ( "[%d] make fifo... \n " , getpid ());
int stats = mkfifo ( fifo_name , 0777 );
if ( stats != 0 )
{
printf ( "[%d] make fifo error. \n " , getpid ());
return - 1 ;
}
}
fifo读写 如果fifo管道文件已经存在, 可以通过open打开, 通过write写入.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// fifo_write.c
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <limits.h>
#include <string.h>
static const char * fifo_name = "./fifo_pipe" ;
int main ()
{
if ( access ( fifo_name , F_OK ) == - 1 )
{
printf ( "[%d] make fifo... \n " , getpid ());
int stats = mkfifo ( fifo_name , 0777 );
if ( stats != 0 )
{
printf ( "[%d] make fifo error. \n " , getpid ());
return - 1 ;
}
}
int fifo_fd = open ( fifo_name , O_WRONLY );
printf ( "[%d] writer open fifo fd %d \n " , getpid (), fifo_fd );
if ( fifo_fd != - 1 )
{
char msg [ 128 ] = "fifo write." ;
int write_stat = write ( fifo_fd , msg , sizeof ( msg ));
printf ( "[%d] fifo write[%d]: '%s' \n " , getpid (), write_stat , msg );
}
close ( fifo_fd );
return 1 ;
}
如果fifo管道文件已经存在, 可以通过open打开, 通过read读出.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// fifo_read.c
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <limits.h>
#include <string.h>
static const char * fifo_name = "./fifo_pipe" ;
int main ()
{
if ( access ( fifo_name , F_OK ) == - 1 )
{
printf ( "[%d] reader get fifo error. \n " , getpid ());
return - 1 ;
}
printf ( "[%d] read prepare open fifo. \n " , getpid ());
int fifo_fd = open ( fifo_name , O_RDONLY );
printf ( "[%d] open fifo fd %d \n " , getpid (), fifo_fd );
if ( fifo_fd != - 1 )
{
char msg [ 128 ];
int read_stat = read ( fifo_fd , msg , sizeof ( msg ));
printf ( "[%d] fifo read[%d]: '%s' \n " , getpid (), read_stat , msg );
}
close ( fifo_fd );
return 1 ;
}
编译两个文件:
1
2
gcc -o fifo_read ./fifo_read.c
gcc -o fifo_write ./fifo_write.c
如果我们先执行fifo_write再执行fifo_read, fifo_write正常执行和退出, 但是fifo_read会阻塞不退出. 如果我们先执行fifo_read再执行fifo_write, 则fifo_read会先阻塞不退出, 待执行fifo_write并写入fifo后, fifo_read从fifo读取成功, 并退出.
关于fifo的read和write阻塞操作, 可以有以下结论:
以O_RDONLY读和O_WRONLY写时, 如果只有进程读, 没有进程写, 则读端会阻塞, 直到有进程写; 以O_RDONLY读和O_WRONLY写时, 如果只有进程写, 没有进程读, 写端不会阻塞(网上查了几份资料的结论时会阻塞, 但是实验代码是不会阻塞的(TODO:官方说法待查证)); 可以验证, 如果以O_RDONLY|O_WRONLY打开, 依然正常工作, 但是无法保证fifo的时序, 这时候A进程write的数据也可能从A进程read出来. 所以如果要fifo实现全双工, 比较简单的方式同pipe, 使用两个fifo实现.
小结 我们简单使用mkfifo创建了fifo文件, 并且使用open, read, write实现了对fifo的操作, 以上总结:
fifo是一个真实存在的文件, 可以在文件系统中找到; fifo数据存储在内核内存的缓存区中, 不会写入到fifo文件; 以O_RDONLY读时, 如果没有写端写入数据, 则open会阻塞; fifo可以全双工, 但是可以使用两个fifo解决时序问题; 同pipe, fifo也依赖pipe capacity和PIPE_BUF决定缓存上限和保证原子性的最大Size;