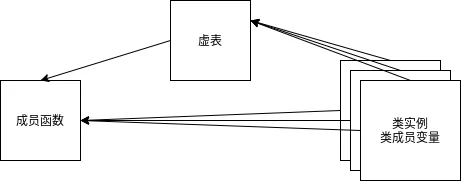
在《C++类的内存分布》中, 我们使用gdb大概了解了C++类的内存结构, 并得到了以下结论:
- 类成员函数只有一份,所有实例共享
- 类的成员变量有多份,不同实例维护不同的成员变量
- 即使是继承关系,派生类的成员变量也只是基类的复制体,而不是指向同一块内存
- 派生类会把从基类继承过来的成员变量当做自己的普通成员变量一样看待
- 类的虚表只有一份,所有实例共享
- 编译器在编译的时候, 通过给类添加
__vptr指针指向虚表而得到虚表地址.
本文主要目的是扩展vptr和vtable部分, 深入了解C++多态的实现原理.
以下环境基于x86-64架构下的gcc 11.1编译器. 测试代码在这里.
带virtual的类的内存结构
上文中, 我们得到了这样的类内存结构:
 结构图
结构图
在这里有两个疑问:
- 类是怎么指向虚表的?
- 虚表怎么指向函数的?
我们先来看结论, 再一起研究怎么得到这个结论:
vptr和vtable
问题1: 类是怎么指向虚表的?
我们可以验证下面一段代码, 输出的值是多少?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| #include <iostream>
using namespace std;
class Base {
public:
Base(){}
virtual ~Base(){
cout << "release Base" << endl;
}
virtual void vfunc1(){
int a = 1;
cout << "hello vfunc1 " << a << endl;
}
virtual void vfunc2(){
double a = 1.111;
cout << "hello vfunc2 " << a << endl;
}
virtual void vfunc3(){
char a =64;
cout << "hello vfunc3 " << a << endl;
}
void func_s1() {
int a = 1;
cout << "hello func_s1 " << a << endl;
}
};
int main()
{
cout << sizeof(Base) << endl;
return 1;
}
|
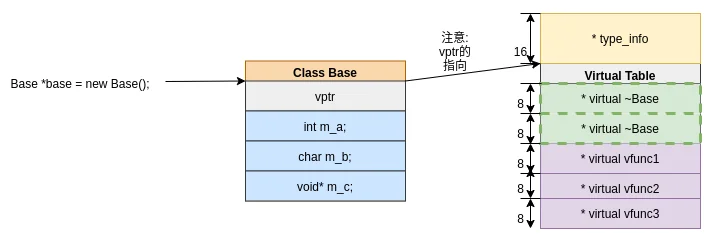
编译运行, 可以看到输出值是8. 根据上文的结论, 我们知道, 如果类里面有virtual关键词, 则会生成一个vptr变量指向虚表. 现在可以断定, 这里的8, 就是vptr指针的占位.
一般, 我们可以直接通过类头指针直接拿到vptr. 看下面一段代码:
1
2
3
4
5
6
| Base *base = new Base();
using uint64 = unsigned long long;
using func_type = void*(void);
uint64 vptr_base_v = *reinterpret_cast<uint64 *>(base);
uint64 *vptr_base = reinterpret_cast<uint64 *>(vptr_base_v);
|
我们把base指针重新解释为uint64*, 因为按照Base*的内存结构不是我们想要的, 所以要把"地址解释为地址", 换句话说, 并解引用得到vptr_base_v. 这里用uint64是为了方便我们后续查看和重新解释指针. 现在vptr_base_v就是vtable地址的值了. 接下来, 对vptr_base_v重新解释, 将uint64解释为uint64*得到vptr_base. 现在vptr_base真正是C++编译器可以认识的地址, 并且指向vtable.
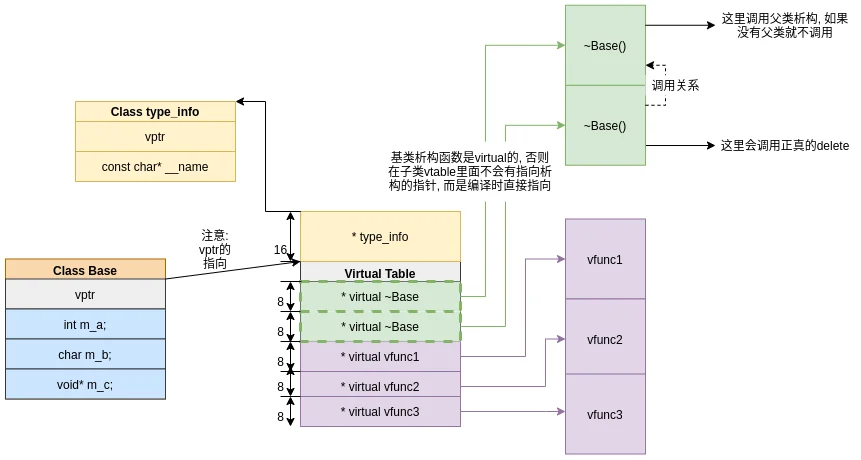
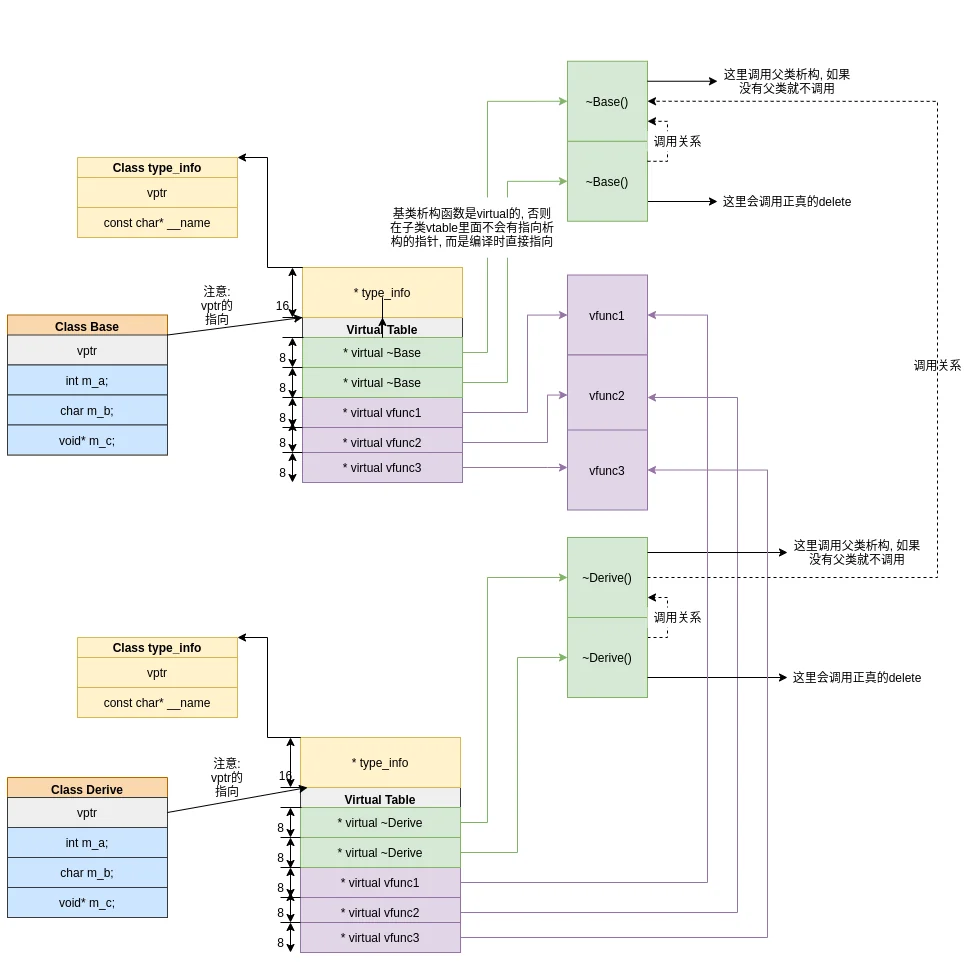
现在可以知道类怎么得到vptr, vptr又是怎么指向vtable的了:vptr到vtable
问题2: 虚表怎么指向函数的?
以上, 我们拿到了vtable. table类设计一般都比较容易猜想, 虚函数指针会"一列一列"的排列在vtable上.
首先, 直接打印函数地址, 作为参照:
1
2
3
4
5
6
| void *base_vfunc1_void = reinterpret_cast<void *>(&Base::vfunc1);
uint64 base_vfunc1 = reinterpret_cast<uint64>(base_vfunc1_void);
void *base_vfunc2_void = reinterpret_cast<void *>(&Base::vfunc2);
uint64 base_vfunc2 = reinterpret_cast<uint64>(base_vfunc2_void);
void *base_vfunc3_void = reinterpret_cast<void *>(&Base::vfunc3);
uint64 base_vfunc3 = reinterpret_cast<uint64>(base_vfunc3_void);
|
这几个输出是:
1
2
3
4
| base::vfunc*
vfunc1 0x401aca
vfunc2 0x401b0c
vfunc3 0x401b58
|
再来尝试分析虚函数在虚表中的定位:
1
2
3
4
5
| //*reinterpret_cast<uint64 *>(vptr_base + 0)
//*reinterpret_cast<uint64 *>(vptr_base + 1)
uint64 vptr_base_vfunc1 = *reinterpret_cast<uint64 *>(vptr_base + 2);
uint64 vptr_base_vfunc2 = *reinterpret_cast<uint64 *>(vptr_base + 3);
uint64 vptr_base_vfunc3 = *reinterpret_cast<uint64 *>(vptr_base + 4);
|
第0和1是对不上的, 尝试2-4, 可以得到以下地址:
1
2
3
4
| base vptr base::vfunc*
vfunc1 0x401aca 0x401aca
vfunc2 0x401b0c 0x401b0c
vfunc3 0x401b58 0x401b58
|
和函数地址是匹配的, 但是0和1是什么? 我们可以打印0和1的地址:
1
2
| uint64 vptr_base_v0 = *reinterpret_cast<uint64 *>(vptr_base + 0);
uint64 vptr_base_v1 = *reinterpret_cast<uint64 *>(vptr_base + 1);
|
得到:
1
2
3
| base vptr
0 0x401a66
1 0x401a9e
|
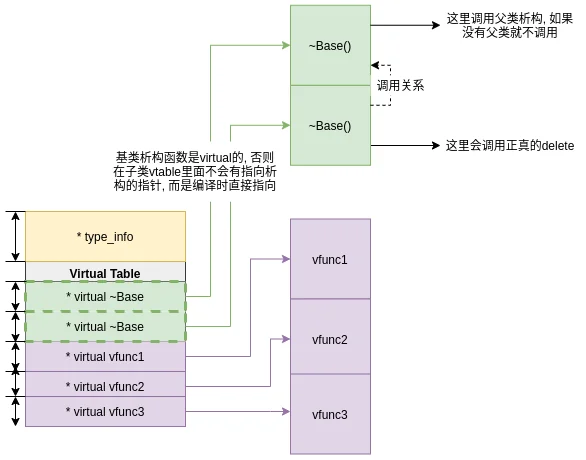
再看汇编, 可以知道0和1分别对应两个虚析构函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| # Base::~Base():
0x401a66: push rbp
mov rbp,rsp
sub rsp,0x10
mov QWORD PTR [rbp-0x8],rdi
mov edx,0x402370
mov rax,QWORD PTR [rbp-0x8]
mov QWORD PTR [rax],rdx
mov esi,0x402008
mov edi,0x4040c0
call 401080 <std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*)@plt>
mov esi,0x401050
mov rdi,rax
call 4010b0 <std::ostream::operator<<(std::ostream& (*)(std::ostream&))@plt>
nop
leave
ret
nop
# Base::~Base():
0x401a9e: push rbp
mov rbp,rsp
sub rsp,0x10
mov QWORD PTR [rbp-0x8],rdi
mov rax,QWORD PTR [rbp-0x8]
mov rdi,rax
call 401a66 <Base::~Base()>
mov rax,QWORD PTR [rbp-0x8]
mov esi,0x8
mov rdi,rax
call 4010a0 <operator delete(void*, unsigned long)@plt>
leave
ret
nop
# ...
|
以上, 我们知道怎么从vtable指向函数了:
vtable到vfunc
问题3: 怎么调用虚函数的?
(本小结2022年3月11日更新)
参考以上示例代码:
1
2
3
4
5
| Base *base = new Base();
D1 *d1 = new D1();
base->vfunc1();
d1->vfunc1();
|
其汇编代码是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| mov edi,0x8
call 401090 <operator new(unsigned long)@plt>
mov rbx,rax
mov rdi,rbx
call 401a4e <Base::Base()>
mov QWORD PTR [rbp-0x18],rbx
mov edi,0x8
call 401090 <operator new(unsigned long)@plt>
mov rbx,rax
mov rdi,rbx
call 401c20 <D1::D1()>
mov QWORD PTR [rbp-0x20],rbx
mov rax,QWORD PTR [rbp-0x18]
mov rax,QWORD PTR [rax]
add rax,0x10
mov rdx,QWORD PTR [rax]
mov rax,QWORD PTR [rbp-0x18]
mov rdi,rax
call rdx
|
按照我们的代码顺序,先后构造了两个类Base和D1。然后在汇编的第三小节,开始执行函数base->vfunc1();,其流程是:
- 拿到
Base的地址,其实对应的就是vptr:
1
2
| mov rax,QWORD PTR [rbp-0x18]
mov rax,QWORD PTR [rax]
|
- 计算
vfunc1的偏移,增加16B相当于跳过了虚函数表开头的两个析构函数地址,所以得到了vfunc1的地址:
1
2
| add rax,0x10
mov rdx,QWORD PTR [rax]
|
- 调用函数
vfunc1,和常规调用一样,这里也需要保存当前的环境,然后call rdx:
1
2
3
| mov rax,QWORD PTR [rbp-0x18]
mov rdi,rax
call rdx
|
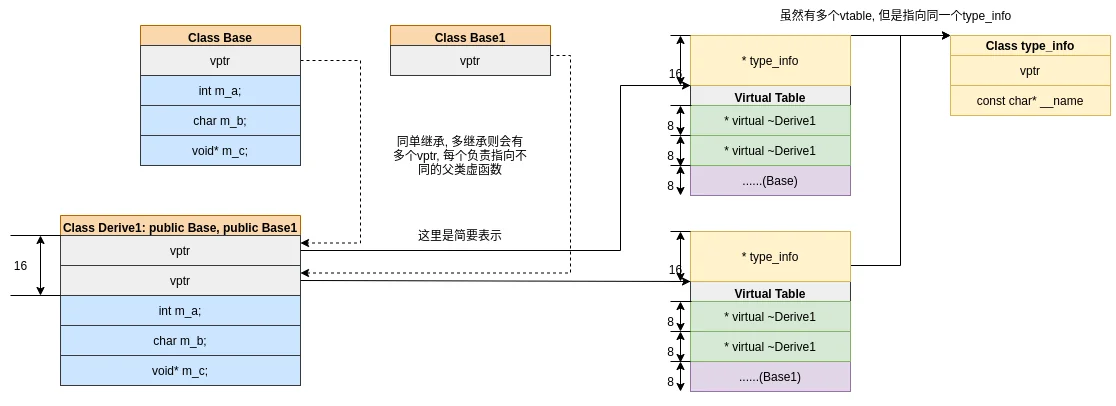
单继承
以上, 我们知道了一个基类的内存分布, 如果是单继承的子类呢?
1
2
3
4
5
6
7
| class D1 : public Base{
public:
D1(){}
virtual ~D1(){
cout << "release D1" << endl;
}
};
|
类比第一节, 可以拿到子类的vtable:
1
2
3
| D1 *d1 = new D1();
uint64 vptr_d1_v = *reinterpret_cast<uint64 *>(d1);
uint64 *vptr_d1 = reinterpret_cast<uint64 *>(vptr_d1_v);
|
以及子类的vtable的指向:
1
2
3
| uint64 vptr_base_vfunc1 = *reinterpret_cast<uint64 *>(vptr_base + 2);
uint64 vptr_base_vfunc2 = *reinterpret_cast<uint64 *>(vptr_base + 3);
uint64 vptr_base_vfunc3 = *reinterpret_cast<uint64 *>(vptr_base + 4);
|
可以得到输出:
1
2
3
4
| d1 vptr base vptr base::vfunc*
vfunc1 0x401aca 0x401aca 0x401aca
vfunc2 0x401b0c 0x401b0c 0x401b0c
vfunc3 0x401b58 0x401b58 0x401b58
|
子类相对于复制了父类的vtable, 但是需要注意这是两个不同的vtable:
1
2
| base d1
0x402370 0x402310
|
再来观察子类vtable的0和1号元素:
1
2
| uint64 vptr_d1_v0 = *reinterpret_cast<uint64 *>(vptr_d1 + 0);
uint64 vptr_d1_v1 = *reinterpret_cast<uint64 *>(vptr_d1 + 1);
|
得到:
1
2
3
| d1 vptr base vptr
0 0x401c48 0x401a66
1 0x401c8c 0x401a9e
|
子类vtable的0号元素和1号元素和父类指向不同, 继续观察汇编结果, 可以发现子类vtable的0号和1号元素指向的是子类的两个析构函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| # D1::~D1():
0x401c48 push rbp
mov rbp,rsp
sub rsp,0x10
mov QWORD PTR [rbp-0x8],rdi
mov edx,0x402310
mov rax,QWORD PTR [rbp-0x8]
mov QWORD PTR [rax],rdx
mov esi,0x40204d
mov edi,0x4040c0
call 401080 <std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*)@plt>
mov esi,0x401050
mov rdi,rax
call 4010b0 <std::ostream::operator<<(std::ostream& (*)(std::ostream&))@plt>
mov rax,QWORD PTR [rbp-0x8]
mov rdi,rax
call 401a66 <Base::~Base()>
nop
leave
ret
nop
# D1::~D1():
0x401c8c push rbp
mov rbp,rsp
sub rsp,0x10
mov QWORD PTR [rbp-0x8],rdi
mov rax,QWORD PTR [rbp-0x8]
mov rdi,rax
call 401c48 <D1::~D1()>
mov rax,QWORD PTR [rbp-0x8]
mov esi,0x8
mov rdi,rax
call 4010a0 <operator delete(void*, unsigned long)@plt>
leave
ret
nop
|
类比Base类的析构, 可以发现子类的析构会调用Base类的析构, 所以, 现在我们可以得到一个教科书上的结论:
在堆上分配的子类, 执行子类析构会先调用子类的析构函数, 然后再调用父类的析构函数, 最后对子类资源正真执行delete.
(尽管这是很多教科书上已有的结论, 但是现在我们从根源观察到了这个执行流程.)
现在, 我们可以得到单继承的类的内存分布的关系图:
单继承
两个析构函数?
以上, 我们发现虚析构函数在汇编的时候会生成两个析构函数, 有点奇怪.(实际上, 上文中已经给出一些结论了:D)
我们继续拿D1来讲:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| # D1::~D1():
0x401c48 push rbp
mov rbp,rsp
sub rsp,0x10
mov QWORD PTR [rbp-0x8],rdi
mov edx,0x402310
mov rax,QWORD PTR [rbp-0x8]
mov QWORD PTR [rax],rdx
mov esi,0x40204d
mov edi,0x4040c0
call 401080 <std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*)@plt>
mov esi,0x401050
mov rdi,rax
call 4010b0 <std::ostream::operator<<(std::ostream& (*)(std::ostream&))@plt>
mov rax,QWORD PTR [rbp-0x8]
mov rdi,rax
call 401a66 <Base::~Base()>
nop
leave
ret
nop
# D1::~D1():
0x401c8c push rbp
mov rbp,rsp
sub rsp,0x10
mov QWORD PTR [rbp-0x8],rdi
mov rax,QWORD PTR [rbp-0x8]
mov rdi,rax
call 401c48 <D1::~D1()>
mov rax,QWORD PTR [rbp-0x8]
mov esi,0x8
mov rdi,rax
call 4010a0 <operator delete(void*, unsigned long)@plt>
leave
ret
nop
|
因为父类的析构函数是virtual的, 所以子类"继承了"父类的析构函数, 这里可以类比普通的虚函数. 又因为析构函数有默认函数, 所以必然会重写父类的析构函数.
先看第一个析构函数0x401c48, 它的作用一部分是执行了用户自定义的析构函数, 然后再调用基类的析构函数~Base().
再看第二个析构函数0x401c8c, 它会先调用第一个析构函数, 然后再调用delete.
我们执行delele的时候调用的是第二个析构函数, 因此可以保证会析构子类和父类, 并且delete子类的资源.
如果我们测试以下代码:
可以发现调用的会是第一个析构函数:
1
| call 401c48 <D1::~D1()>
|
因为资源在栈上分配, 所以也无需关心资源分配的问题了.
现在, 我们可得到关于为什么要有两个析构函数的结论:
两个析构函数可以解决堆上分配和栈上分配的问题, 如果是堆分配则调用第二个析构函数, 如果是栈分配则调用第一个析构函数
多继承
多继承和单继承是类似的. 多继承可能包含多个vptr和vtable.
多继承
总结
本文可以得到的几个结论:
- vptr一般在类内存的头部(和编译器相关)
- 如果基类析构函数是虚函数, 则vtable的前两项会指向析构函数
(有点累…过两天继续)