在《glibc-exit源码阅读》和《《UCB CS61a SICP Python 中文》一周目笔记(一)》中我们提到了栈帧的概念,但是我对这个概念越来越模糊,栈帧是什么?栈帧是不是包含了程序的执行指令?
本文的说法或者结果可能因为不同平台或不同编译器而产生差别,但是本文的目的不是为了搞清楚某一个平台/编译器下的栈帧,而是为了搞清楚栈帧整体的概念,因此即使不同平台/编译器下,也应该不会有很大差别。
栈帧
按照约定,以下rbp表示栈底,rsp表示栈顶,栈向低地址方向增长。
来看一段代码,以下使用x86-64 clang 13.0.0版本编译,需要开启O0优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int func(int v1, int v2, int v3, int v4, int v5, int v6, int v7, int v8, int v9, int v10) {
int n1 = v1 + 1;
int n10 = v10 + 1;
int nv = v1 + v2 + v3 + v4 + v5 + v6 + v7 + v8 + v9 + v10;
int vv[100]{1};
int vv10 = vv[10];
char cv[10] = "hello";
return nv;
}
int main() {
int a = 1;
int b = 10;
int c = 11;
func(a, 2, 3, 4, 5, 6, 7, 8, 9, b);
return 1;
}
|
得到main和func的汇编结果如下,下面来分析汇编流程。
首先看main函数的汇编:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| main:
push rbp
mov rbp,rsp
sub rsp,0x30
mov DWORD PTR [rbp-0x4],0x0
mov DWORD PTR [rbp-0x8],0x1
mov DWORD PTR [rbp-0xc],0xa
mov DWORD PTR [rbp-0x10],0xb
mov edi,DWORD PTR [rbp-0x8]
mov eax,DWORD PTR [rbp-0xc]
mov esi,0x2
mov edx,0x3
mov ecx,0x4
mov r8d,0x5
mov r9d,0x6
mov DWORD PTR [rsp],0x7
mov DWORD PTR [rsp+0x8],0x8
mov DWORD PTR [rsp+0x10],0x9
mov DWORD PTR [rsp+0x18],eax
call 401130 <func(int, int, int, int, int, int, int, int, int, int)>
mov eax,0x1
add rsp,0x30
pop rbp
ret
|
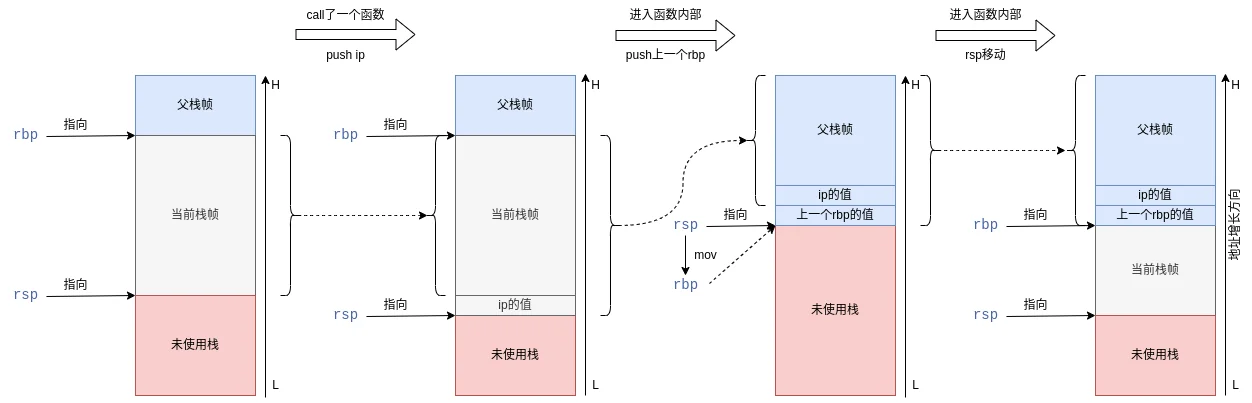
保存栈底和扩展栈
第一步是准备操作:
1
2
3
| push rbp
mov rbp,rsp
sub rsp,0x30
|
把上一次的rbp入栈,然后把rbp的值置为rsp,也就是说,目前为止,栈底就是上一次的栈顶,然后将栈顶寄存器rsp下移0x30个字节,这里约定了,64位机上,rsp偏移需要是16的整数倍。
第一步操作就是把上一次的栈顶作为现在的栈底,然后把栈顶下移一段距离,以增加当前栈的长度。
局部变量
第二步操作初始化了一些局部变量:
1
2
3
4
| mov DWORD PTR [rbp-0x4],0x0
mov DWORD PTR [rbp-0x8],0x1
mov DWORD PTR [rbp-0xc],0xa
mov DWORD PTR [rbp-0x10],0xb
|
如上,按照代码顺序,局部变量按照从高地址到低地址排列,比如rbp-0x8代表变量a,rbp-0xc代表变量b。但是也有一个问题,rbp-0x4代表的是什么?这里存在疑问,不像是为了内存对齐,因为即使我让main函数中的变量8B对齐了,这个rbp-0x4还是存在,但是使用gcc编译的话就不存在了,所以也可以暂时猜想为编译器的某优化目的。
函数入参准备
第三步是准备函数入参,准备好后就要调用函数了:
1
2
3
4
5
6
7
8
9
10
11
| mov edi,DWORD PTR [rbp-0x8]
mov eax,DWORD PTR [rbp-0xc]
mov esi,0x2
mov edx,0x3
mov ecx,0x4
mov r8d,0x5
mov r9d,0x6
mov DWORD PTR [rsp],0x7
mov DWORD PTR [rsp+0x8],0x8
mov DWORD PTR [rsp+0x10],0x9
mov DWORD PTR [rsp+0x18],eax
|
这里的计算顺序是从左往右,如果是gcc编译器,计算顺序则是从右往左,计算顺序和入参顺序在《i++和++i在函数入参时的一些问题》和《《UCB CS61a SICP Python 中文》一周目笔记(一)》有讲过。
这里还需要注意的就是这几句:
1
2
3
4
| mov edi,DWORD PTR [rbp-0x8]
mov eax,DWORD PTR [rbp-0xc]
##...
mov DWORD PTR [rsp+0x18],eax
|
在开始的时候就拿到了a(rbp-0x8)和b(rbp-0xc)两个变量,但是这里入参准备阶段实际只用到a,b在最后才准备好,被写入了rsp+0x18。
这里的地址也是值得关注的:
1
2
3
4
| mov DWORD PTR [rsp],0x7
mov DWORD PTR [rsp+0x8],0x8
mov DWORD PTR [rsp+0x10],0x9
mov DWORD PTR [rsp+0x18],eax
|
注意到,这部分都是用的rsp加一个偏移得到的地址,而不是rbp减偏移得到的地址,并且这些参数是被写入了内存,而前6个参数是被写入的寄存器。这里的共识是,如果函数参数个数少于6个,则使用寄存器传递,如果大于6个,则多余的参数会使用内存传递,是不是所有情况都这样,暂时不必要追究,大部分情况都是这样的。
至于为什么用rsp加一个偏移来传递参数,我认为这是编译器的优化问题,使用gcc编译器的话,就是使用push指令,相当于是使用rsp减一个偏移来传递参数。为什么说是编译器优化问题呢?看这一段:
在开头已经分析过了,这是移动了栈顶指针,现在栈的大小是48B(如果是gcc的话,分配的是16B),对于4个int参数,3个int变量,和上述说的4B的未知空间,48B > (4 * 4 + 3 * 4 + 4)B是满足要求的,所以为了利用好空间,这样操作是可能的。
函数调用
第四步就是函数调用了:
1
| call 401130 <func(int, int, int, int, int, int, int, int, int, int)>
|
这里call指令需要拆解一下,方便后续分析,call指令相当于:
1
2
| push ip
jmp 401130 <func(int, int, int, int, int, int, int, int, int, int)>
|
子函数
现在我们进入到了函数内部,回忆在这之前我们做了什么工作? 保存了调用者的ip指针(或者叫pc指针),这里对应就是main函数中call的后一句,所以我们可以方便的恢复到jmp之后。下面来看子函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| func(int, int, int, int, int, int, int, int, int, int):
push rbp
mov rbp,rsp
sub rsp,0x1d0
mov eax,DWORD PTR [rbp+0x28]
mov eax,DWORD PTR [rbp+0x20]
mov eax,DWORD PTR [rbp+0x18]
mov eax,DWORD PTR [rbp+0x10]
mov DWORD PTR [rbp-0x4],edi
mov DWORD PTR [rbp-0x8],esi
mov DWORD PTR [rbp-0xc],edx
mov DWORD PTR [rbp-0x10],ecx
mov DWORD PTR [rbp-0x14],r8d
mov DWORD PTR [rbp-0x18],r9d
mov eax,DWORD PTR [rbp-0x4]
add eax,0x1
mov DWORD PTR [rbp-0x1c],eax
mov eax,DWORD PTR [rbp+0x28]
add eax,0x1
mov DWORD PTR [rbp-0x20],eax
mov eax,DWORD PTR [rbp-0x4]
add eax,DWORD PTR [rbp-0x8]
add eax,DWORD PTR [rbp-0xc]
add eax,DWORD PTR [rbp-0x10]
add eax,DWORD PTR [rbp-0x14]
add eax,DWORD PTR [rbp-0x18]
add eax,DWORD PTR [rbp+0x10]
add eax,DWORD PTR [rbp+0x18]
add eax,DWORD PTR [rbp+0x20]
add eax,DWORD PTR [rbp+0x28]
mov DWORD PTR [rbp-0x24],eax
lea rdi,[rbp-0x1c0]
xor esi,esi
mov edx,0x190
call 401030 <memset@plt>
mov DWORD PTR [rbp-0x1c0],0x1
mov eax,DWORD PTR [rbp-0x198]
mov DWORD PTR [rbp-0x1c4],eax
mov rax,QWORD PTR ds:0x402004
mov QWORD PTR [rbp-0x1ce],rax
mov ax,WORD PTR ds:0x40200c
mov WORD PTR [rbp-0x1c6],ax
mov eax,DWORD PTR [rbp-0x24]
add rsp,0x1d0
pop rbp
ret
cs nop WORD PTR [rax+rax*1+0x0]
nop DWORD PTR [rax+rax*1+0x0]
|
第一步我们保存了rbp寄存器,这里的rbp寄存器保存了什么值?就是调用者的栈底指针,这里对应的就是main的栈底指针。所以目前为止,我们保存了main的栈底和pc指针,已经只要恢复这两个指针,我们又可以回到main工作了!
第二步把func帧的栈底设置为了main的栈顶,所以这两个栈连续了~,然后扩展了func函数的栈,大小是0x1d0。
第三步是入参:
1
2
3
4
5
6
7
8
9
10
| mov eax,DWORD PTR [rbp+0x28]
mov eax,DWORD PTR [rbp+0x20]
mov eax,DWORD PTR [rbp+0x18]
mov eax,DWORD PTR [rbp+0x10]
mov DWORD PTR [rbp-0x4],edi
mov DWORD PTR [rbp-0x8],esi
mov DWORD PTR [rbp-0xc],edx
mov DWORD PTR [rbp-0x10],ecx
mov DWORD PTR [rbp-0x14],r8d
mov DWORD PTR [rbp-0x18],r9d
|
对照入参准备阶段,参数计算是从左往右,这里入参是从右往左。现在我们观察到了函数入参的结论了。另外,这几个地址可以关注一下:
1
2
3
4
| mov eax,DWORD PTR [rbp+0x28]
mov eax,DWORD PTR [rbp+0x20]
mov eax,DWORD PTR [rbp+0x18]
mov eax,DWORD PTR [rbp+0x10]
|
和main参数准备的地址相比,还偏移了0x10个字节,为什么?因为call指令的时候保存了pc指针,进入到func函数的时候又保存了rbp指针,一共是16B,对应就是增加了0x10。
总之,目前为止,我们将main函数传入的参数都保存在了func函数栈帧里面。后续的赋值语句我们就不分析了,不过需要关在下面两部分:
1
2
3
4
5
| lea rdi,[rbp-0x1c0]
xor esi,esi
mov edx,0x190
call 401030 <memset@plt>
mov DWORD PTR [rbp-0x1c0],0x1
|
这里用于分配和初始化vv[100]这个数组,调用memset初始化为0,然后给第一个元素初始化为1,是否调用memset初始化是编译器行为,并不是所有编译器都会帮助你初始化一个数组,这是需要注意的。
1
2
3
4
| mov rax,QWORD PTR ds:0x402004
mov QWORD PTR [rbp-0x1ce],rax
mov ax,WORD PTR ds:0x40200c
mov WORD PTR [rbp-0x1c6],ax
|
这部分用于给cv[10]初始化为"hello",可以看到"hello"对应在了ds区,并且发现这里是有复制操作的,怎么复制的就先不关心了,这也能给我们提醒,如果非必要的话,可以直接使用指针指向"hello",而不是用一个数组。
最后就是func的退出,这部分是和main类似的,就不介绍了。
 函数调用的栈帧
函数调用的栈帧
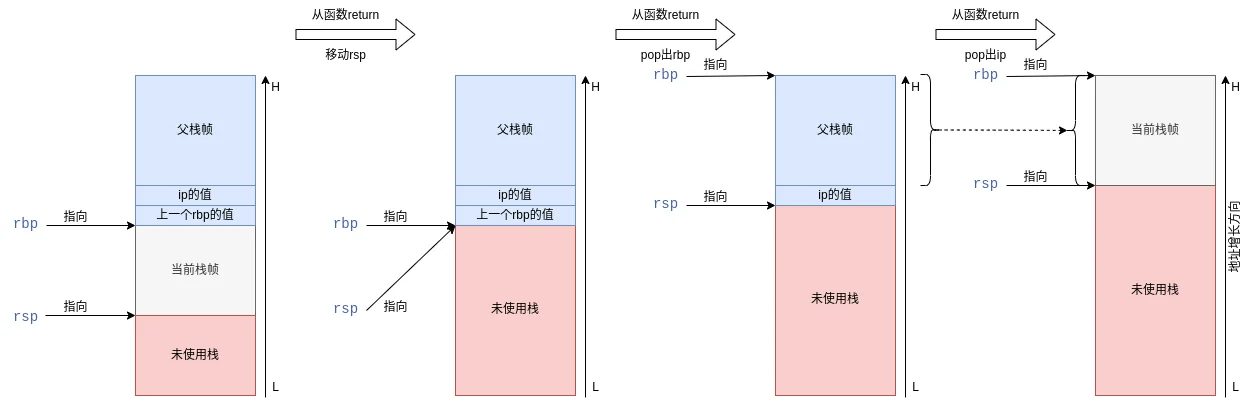
函数退出
上述函数调用之后,就需要退出main函数了:
1
2
3
4
| mov eax,0x1
add rsp,0x30
pop rbp
ret
|
我开始比较疑惑,为什么会把0x1赋值给eax寄存器?原来是main函数返回了1,所以返回值先给了eax寄存器。赋值完返回值后,会把栈顶寄存器移动到栈底,这里对应的就是add rsp,0x30,然后恢复调用者的栈底,main的调用者就是__libc_start_main,在《glibc-exit源码阅读》已经介绍过了。ret指令则会pop出ip寄存器,相当于恢复到调用者上次执行的位置。
函数退出的栈帧
黑魔法
通过上面的分析,可以知道,函数在调用子函数后,栈会向下增长,子函数返回后,栈会减小,栈底和栈顶又会回到调用者的位置,但是并没有清空子函数的栈记录。
因此,我们可以实现一个黑魔法,在main函数里面获得func函数中的局部变量!如下就是我们的攻击函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #include <stdio.h>
int func(int v1, int v2, int v3, int v4, int v5, int v6, int v7, int v8, int v9, int v10) {
int n1 = v1 + 1;
int n10 = v10 + 1;
int nv = v1 + v2 + v3 + v4 + v5 + v6 + v7 + v8 + v9 + v10;
int vv[100]{1};
int vv10 = vv[10];
char cv[10] = "hello";
return nv;
}
int main() {
int a = 1;
int b = 10;
int c = 11;
func(a, 2, 3, 4, 5, 6, 7, 8, 9, b);
printf("%s\n", (reinterpret_cast<char *>(&a) + 4 + 4 - 16 * 3 - 8 - 8 - 462));
return 1;
}
|
关键部分是:
1
| (reinterpret_cast<char *>(&a) + 4 + 4 - 16 * 3 - 8 - 8 - 462)
|
我们来分析每个数字的含义:
- 第一个
+ 4,因为变量a占4B,为了回到main的栈底,我们先上移4B - 第二个
+ 4,暂时没找到原因,通过分析clang的汇编才能找到这多出来的4B,总之,还需要上移4B - 16 * 3,以上我们回到了main的栈底,现在需要到main的栈顶,所以下移16 * 3- 8 - 8, 现在走到了main的栈顶,调用func还有两个push操作,分别是push``ip和rbp,所以再下移两个8B- 462, 现在走到了func的栈底,为了得到cv的值,我们需要知道cv的偏移, cv的偏移是0x1ce对应就是462
所以,以上printf部分,可以在main函数打印func函数中的局部变量,这里就会打印"hello"。
不过,还是有疑问,- 462是怎么来的,如果只分析func的局部变量的大小,计算出来的不是462,而是(100 + 4 + 6) × 4 + 10 = 450,通过汇编分析,多出来的12B是在vv[100]这个数组初始化过程中产生的,可以尝试增加另外一个数组,也会发现会多出来几个字节的空间,这里就不追究了。
假想攻击:
通过以上分析,我们知道程序执行过程中会在程序栈中留下痕迹。如果某软件会把用户密码明文地临时保存在一个局部变量中,是不是可以通过hook一些基础函数,比如hook glibc的某些函数来入侵软件的进程栈呢?入侵之后就可以获取到整个进程栈(一般也就8MB),然后通过实时分析(比如关键词匹配等等)进程栈来猜解用户密码。不过,如果多线程的话,线程栈可能会和进程栈有区别,会增加数据量。
结论
现在来回答一下我的疑问:栈帧是什么?栈帧是不是包含了程序的执行指令?
栈帧是栈,是保存程序运行局部变量的栈,是程序栈的一部分,动态增长。栈帧不包含程序的执行指令,但是包含执行指令的地址。