《现代C++白皮书》一周目读后感
摘要
本文是作者对《现代C++白皮书》一周目阅读的总结,回顾了C++从C++98到C++20的发展历程,分析了语言特性和设计哲学的演变。文章强调C++是一门全新的语言,探讨了零开销抽象、多态、RAII等核心概念,并详细介绍了C++11、C++14、C++17和C++20的主要更新,包括移动语义、constexpr、概念和模块等。作者还反思了学习编程语言的方式,认为理解语言设计思想和历史对编程能力的提升至关重要。
最近在读C++之父 Bjarne Stroustrup 关于 HOPL4(History of Programming Language,约十五年举办一次)会议的论文,以下称白皮书。主要讲述的是C++98到C++20的语言发展历史,包括一些语言特性和基础库的由来和相关讨论,以及为什么有些是语言特性,有些变成了基础库。了解语言发展历史,有助于理解语言设计的核心思想。
类似的,这是一篇一周目的读后感(22.06.18开始写…到现在三个多月了, 实际上差不多二周目),同SICP系列(目前还在一周目…)的理念,我认为上述论文也是值得多次拜读的,积累一定知识后再开启多周目肯定会有不一样的收获。
本篇读后感和SICP笔记的区别是,读后感是读完全文的所想,笔记是读完每一章节的所学和所想。
中文译版下载:在这里
C++是一门全新的语言
首先,我们需要再一次重新认识到,C++并不是C的补充,也不是C的扩展,C++是一门全新的语言,我甚至认为这种认识是十分重要的。认识到C++是一门全新的语言将对我们的编码风格、组织以及思考方式都有帮助。在Stroustrup早期著作《C++语言的设计和演化》中,有这样一张图说明这种语言的演化关系:
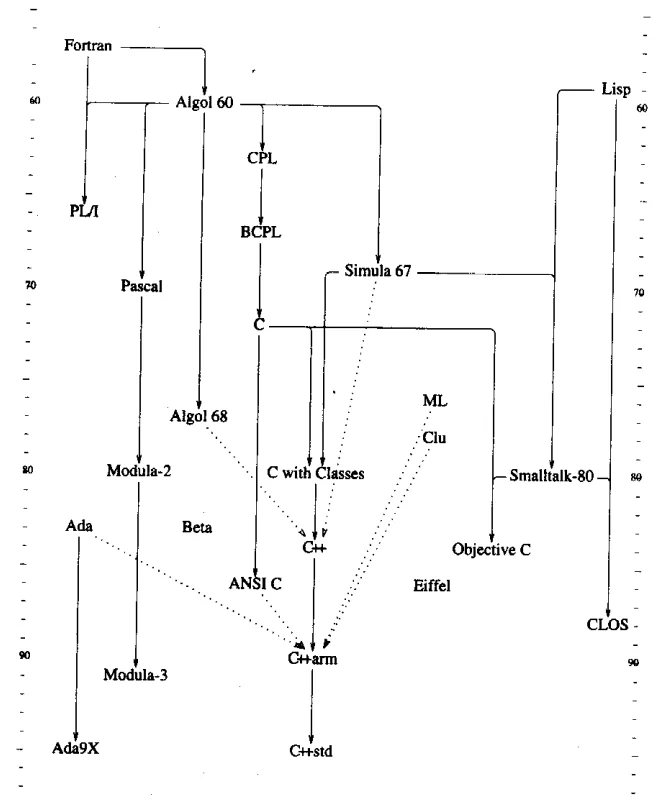
同样的,因为我最近在学习Objective-C,有很多人说OC是C语言的超集,实际上是不对的,如果把OC认为是C语言的超集那应该是大错特错了。我们只能说,OC兼容了或者大部分兼容了C,两个不是同一种东西,包括代码的编写和设计思想都不应该一样。需要了解这种区别,我认为需要了解了解Smalltalk这门语言。
最开始的C with Classes是通过C和Simula演化而来的,而后参考其他诸多语言演化为了C++,当然,就如Stroustrup所说,C++有很多特性也是通过长期实验和实践而得来的,更像是一个经验老道的工程师。
C with Classes最开始的目标是像C一样可以直接而高效的处理硬件,又可以像Simula一样组织代码。我认为C with Classes的说法,可能是将大部分人引入把C++看作是一门面向对象语言这样的一种误区的原因。其实很多教科书或者参考书都会说明(尽管他们的大多数还是说C++是一门面向对象的语言),C++也可以面向过程,函数式编程、泛型编程等等,尽管这些定义会和面向对象有所关联,但是理应区分他们之间的关系,这些定义是关系到代码组织方式和思考方式的。这种认知和“C++是一门全新的语言”一样重要,就如我在工作中经常会看到有人不假思索的就说“把XX定义为一个类”之类的说法,始终觉得很奇怪,万物都是对象吗?我想是的,万物都可以是对象,但是是不是万物都应该看作是对象?值得思考,现在主流观点都说万物皆对象,尽管我对此持怀疑的态度,但是大部分时候不得不随波逐流。
关于C++,我们经常会提到“零开销抽象”,到现在为止我也不能十分地理解该描述地含义,Stroustrup对此的解释是:
- 你不用的东西,你就不需要付出代价
- 你使用的东西,你手工写代码也不会更好
我的个人看法,“零开销抽象”是一种被C++采用,而被诸如Python、Javascript等解释器语言抛弃的设计哲学,因为解释器是runtime的,所以总有用户设计之外的开销,而类似Java因采用JVM机制,所以也不符合“零开销抽象”的设计哲学。在“零开销抽象”的设计框架下,用户或编译器更像是一个专家,需要考虑到更细致的东西,介错人的角色只会出现在用户的脑子里或者编译期(rust的编译器就像是编译期的介错人)。而在一些其他语言中(比如解释型),用户就是用户,不需要考虑太多,专心将思路转化为代码即可,介错人会在运行期出现。
关于C++用户更像一个专家的说法,我想到了一种解释。因为最近在看OC,OC主要参考自Smalltalk的设计思想,Smalltalk的一个思想是–创造性。用户不仅仅是程序的使用者,也是程序的开发者。那么这时候的语言设计就需要简单,用户不需要特别的了解各种不同的硬件构造,他们只需要把他们的想法表达出来即可。换句话说,我的理解是,C++是站在机器角度思考问题的,所以用户需要迎合它;Smalltalk是站在用户角度思考问题的,所以用户只需要关心自己。这么看来,C++用户会渐渐成为专家,而Smalltalk用户会渐渐成为资深用户(产品用户,就好像熟悉Windows系统一样)。(Smalltalk的设计目的,用现在的话语说就是一套操作系统 + 编程语言 + IDE的集成环境,用户在获得计算机后,会学习如何使用计算机,因为计算机的软件和环境全部由Smalltalk编写,那么这个过程中,用户也就慢慢学会了如何使用Smalltalk,那么他就会学会如何编程,而这个过程是不太需要像现在这样专门去学习编程课程的。)
(还是回到C++吧,几个祖师爷级别的语言还是得找时间大概学习学习的。)
早期C++的发展史,是C++类的成长史。从白皮书所列的年表可以看到98年以前C++的发展主要是围绕类来展开的(当然,可能也有其他核心工作,但是我没读过其他HOPL的论文,而白皮书中也为着重介绍早期C++的发展,所以认知到此为止)。Stroustrup提到,C++的核心是构造函数和析构函数,在早期对应的是new和delete操作,但是不仅仅是指代内存,而是一切资源。我认为,不要把析构、构造函数和面向对象同等看待,他们不是包含或者被包含的关系,而更像是有所交集的两个不同集合,包含析构和构造的对象只是面向对象的一种实现方式而已。通过构造和析构,可以演化出C++的RAII设计哲学,这种设计可能成为C++不那么需要GC的论据之一。
在1980年代期间,又为C++类提供了继承、虚函数、重载、纯虚函数的支持。这是C++的类和Python或者Javascript等不同之处,多态迫使C++用户写出更加抽象的代码,迫使用户从问题中寻找更高层次的解释。我遇到有人会比较排斥多态,认为过度封装,但是我个人看来只是能力不够(也可能是认为“可以运行就可以了”,这是很多人会持有的态度,我有时候也会)。
C++98是大多数人学习的第一个C++版本,在98版本中,添加了模板、异常、namespace等语言特性,RAII的技术也是在C++98版本中确立的(很早就是这种技术,只是没有名字),此外,跟随C++98发布的,还有STL、智能指针等标准库。RAII和智能指针的出现否定了C++对GC的需求,namespace将构建复杂而庞大的库变得更容易(C++20的包也可以改变代码的组织方式和编译方式),模板的标准化催生了新的、图灵完备的编程流派–泛型编程(更早的时候也有)。
现在C++的很多特性在21世纪初就已经初见模型,可能因为标准化的原因,很多推迟了十几年、二十几年才得以发布。似乎强大的标准委员会在某些程度上来说,也阻碍了C++的发展和壮大。
C++11是迈向现代化的一步
我刚开始学的C++是C++98,所以学习C++11的时候,颇有一种“这是啥?”的想法,两个版本的跨度对我来说相当不小,而C++11到C++17之间的跨度,却几乎是无感的。当然到了C++20,又有不小的改动,尽管很多概念都是近乎二十年前的。
C++11和之前的版本相比,富有现代感,加入了如下更新:
- auto推导
- 范围for
- 统一初始化
- 移动语义,如右值引用和std::move
- 用nullptr指代空指针
- constexpr函数
- lambda表达式
- 强枚举类型enum class
- 变参模板
- 扩展using意义,类型重命名、别名
- unique_ptr和shared_ptr,扩充了依赖RAII的资源管理指针
- aotmic变量
- 标准thread库
- future-promise、packaged_task模型
- type trait,更丰富的模板元编程
- etc.
我想补充关于对nulltpr的认识。此前我找过一段时间关于nullptr的实现原理,最终得到了一种可信任的解释。nulltpr是语言上面更新,对nulltpr的支持是编译器层面的,而不是简单的认为对NULL的替换。
如果对这些更新分类,我想可以是:
- 用户层面的更新,这里的用户是程序员,减少劳动成本,比如auto推导、范围for、lambda表达式等
- 语言哲学的更新,是对语言认知转变的更新,比如nullptr、移动语义、内存模型等
用户更新偏向上层,语言哲学更新偏向底层。用上一节的话说,用户更新更倾向于smalltalk,让用户更具创造力;语言哲学更新更倾向于C++本身,让用户更像是专家。
言归正传,以上是语言自身的更新和标准库的更新,有部分没有列出,从我的浅见来看,最重要的更新是:
- 移动语义,减少内存拷贝,提高软件性能
- 对模板、类型的支持,丰富元编程技术
- 对内存模型的更新
- 对多线程标准库的支持,再也不用三方库了
我认为,这些更新让C++代码写起来更加现代化(我想的是和Python对比,会比较像了)。因为更多标准库的支持,此前不少复杂的特性、写法也变得更加简单和统一。比如范围for、thread库之类。
此外,C++11还有内存模型上的更新,这可能是最重要的更新,但是我对此暂时还不太了解,因此暂时略过。至于emplace运算之类,我认为是移动语义的附属产品。还有time库、random库之类,因为用的比较少,所以对此了解也不多。
到这里,我也想到了我们大学的C++教材,使用的是C++98的版本 – 说的就是《C++程序设计》。极其复杂和无聊的解说,把对C++语言的学习就当做是对一些条条框框的背诵和记忆,没有为什么,没有怎么来。所以那时候很多同学也学不下去,对这东西没什么兴趣。在我认识的同学里面,应该是没有因为这个教材喜欢上C++的,基本都是完全自学的。
在该译文中,Stroustrup也如是说:
直到 2018 年,我仍能看到 C++98 前的编译器被用于教学。我认为这是对学生的虐待,剥夺了他们接触学习我们 20 多年的进展的机会。
(我们被要求用的编译器是Borland C…)
不过,C++11如此大的变动,也导致了很多公司更新的困难,这意味着很多代码可能需要重写。在我工作一段时间之后,对此有很明显的感觉。公司使用的平台源代码,使用的是C++98的标准,最近几个release版本才可以从中看到部分C++11及以上的特性。公司很多老员工也是使用的C++98标准,或者是C with class。
总结其原因,大概率还是因为老教材不更新,以及版本特性差别较大导致的切换和学习困难。
C++14 - C++17小版本升级
我认为C++14-C++17是C++11的小版本(小数点版本)升级,当然这是个人看法,按照ISO的计划,C++11后的每3年的都是一次(等同的)常规版本升级。
依照Stroustrup的说法,C++14是:
依据大版本和小版本交替发布的计划,C++14的目标是“完成C++11”
其更新概括为:
- 字面量更新和支持数字分隔符
- 变量模板
- 函数返回值auto推导和lambda参数auto推导
- constexpr函数支持局部变量
- 移动捕获
- 按类型访问元组(这部分可以看之前的文章《STL-tuple源码阅读》)
日常用得多的是对auto推导的扩充和对constexpr函数的扩充。
使用auto扩充,可以写出更统一格式代码。对lambda表达式的输入输出基本统一,但是对函数输入来说,目前还没有auto支持。不过,在C++20版本中也指出了这种auto推导相对于template推导的缺陷,在概念引入后,也会慢慢修复这些缺陷。
使得constexpr函数可以支持局部变量,则允许写出更具通用性的编译期代码。可能有利有弊吧。对于程序开发人员来说,将有条件写出性能更好的代码;但是对于编译器开发人员来说,使得提高编译速度这项issue更具挑战性。
C++17被当做了大版本升级,添加了如下内容:
- 构造函数模板推导和推导指引,如可以
shared_lock lck {m};而不用再shared_lock<mutex> lck {m}; - 结构化绑定
- 复制消除,减少拷贝
- 更严格的表达式求值顺序,减少未定义行为,可以参考《i++和++i在函数入参时的一些问题 》
- 对optional、any、variant的支持,any源码可以参考《STL-any源码阅读 》
- etc
可以看到C++17也没有像C++11这样的巨大改动,更多的是补充和优化。
在文中,Stroustrup提到了“结构化绑定”这一特性的由来,他说:
而正当 2015 年 11 月底在科纳 Ville Voutilainen 刚要结束 EWG 会议时,我注意到我们离午饭还有 45 分钟,我觉得小组应该会想要看到这个提案。2015 年科纳的会议是我们冻结 C++17 的功能集的时间点,所以这 45 分钟很关键。我们甚至没时间去另一个小组找到 Herb,我就直接讲了这个提案。EWG 喜欢这个提案,会议纪要说鼓掌以资鼓励;EWG 想要这样的东西。
他说的是关于auto {x,y,z} = f();这类表达式的提案(由Herb Sutter建议),不只是支持tuple,也支持struct的结构化绑定。令我觉得有意思的,他们的工作就像是学生,没有很强的上下级(可能因为他级别本来就高),卡着饭点前的45分钟提出了这个提案,还通过了。很羡慕这种工作氛围。
C++20大版本升级
C++20的大更新就是关于概念的引入。(我目前并没有关心最近的C++20发版工作)
关于概念的写法,我是更偏向于Stroustrup的自然派,当然在C++20中采用的是一种折中写法。
当出现类型的时候,一般想的是“给我一个某某类型”,这是非常具体的;然后出现了模板,这时候会想“随便给我一个XX我就能YY”,这是非常宽泛的,覆盖所有可能性;然后有了enable_if,这时候想的是“给我一个满足XX条件的YY我才能ZZ”,是介于类型和普通模板之间的一种相对比较宽泛的东西。如果用集合描述,类型就是只有一个元素的集合,普通模板是全集,enable_if是子集,这三种描述方法基本可以表达所有可能的组合的情况了。
概念的出现,在我看来是对上述三种情况的统一,而不仅仅是为了简化复杂的enable_if的写法,当然,要是仅凭我现在的认知,我还是认为基础类型是不少的。有了概念之后,普通类型可以描述为“XX类型是类型为XX类型的类型”,普通模板可以描述为“XX类型是类型为任意类型的类型”,enable_if则描述为“XX类型是满足以下YY等条件的类型”。都是共用一套描述方法,所以我会更倾向于自然派写法:
| |
Iteratable是一个概念或者模板,普通类型也可以,但是引入概念之后都当作我们曾经认知的普通类型来看待。Stroustrup一派的想法是让泛型编程变得和普通编程一样,可惜的是,C++20中并没有采用概念自然表示的写法,而是一种复杂的写法和所谓简写法:
最仔细的写法:
| |
稍简化:
| |
简化:
| |
就算最简单的写法,也没有脱离模板的影子,仍然要用一个auto标识符,来说明这是一个概念/模板。
此外的更新还有:
- 引入概念
- 引入模块
- 对协程库的支持
- etc.
对于概念、模块、协程库还得多写写才能深刻体会,概念和模块虽然Stroustrup说是很老的东西了,但是对我来说还是很新,得多写多用多体会;关于协程,此前看过一些实现方法,比如云风的方案。之后会输出关于协程的文章。
关于学习编程语言的观点
这是一段简短的个人观点,现在时间是2022年09月27日。
以我学生时期的思想来说,学习一门编程语言很简单,我一度认为学会某种(比如C、C++)之后再学习其他的就会很简单。所以那时候会学习很多编程语言。
但是现在我并不持有这种观点,如果对C或C++一类有颇深的执念,再学习其他语言可能会更难。我想说的就是“思想、灵魂”。比如Python、JavaScript、C、C++,虽然相似,但是编程思想、代码结构并不是一样的,语言、语法只是皮囊罢了。因为我此前的观点,导致我写Python、JavaScript都会像写C/C++一样,这就是完全没学会嘛!写出来的是四不像。甚至最近在看OC的时候,我还想说,这TM是什么东西,怎么会有这种语言?!其实还是见识少了。
所以,学习编程语言,不只是学习语法、关键词;还需要学习对应语言的编程思想、代码结构、语言发展史(说的就是OC,看了OC的发家史,我才觉得,牛啊,这语言的思想好!!!有意思。)。这就像我们学习外语一样,背单词、学语法总是达不到native speaker的水平,说到底还是我们缺少对语言文化和思想的学习。
虽然这篇HOLP没有对C++知识点的详细叙述,但是其描述的历史过程、提案过程,确实帮助我加深了对C++的理解,也有查漏补缺,也有了解各个版本区别。之后的我将更向C++ native programmer靠近。