clockdiff是iputils库下的一个时间测量工具,用于测量两台设备之间的时间差。基本用法是:
1
clockdiff <destination>
本文主要学习clockdiff测量时间差的原理。
clockdiff运行时,不需要对端也打开clockdiff就能测量时间,这依赖于ICMP协议。
ICMP协议 主要参考一些其他文章:
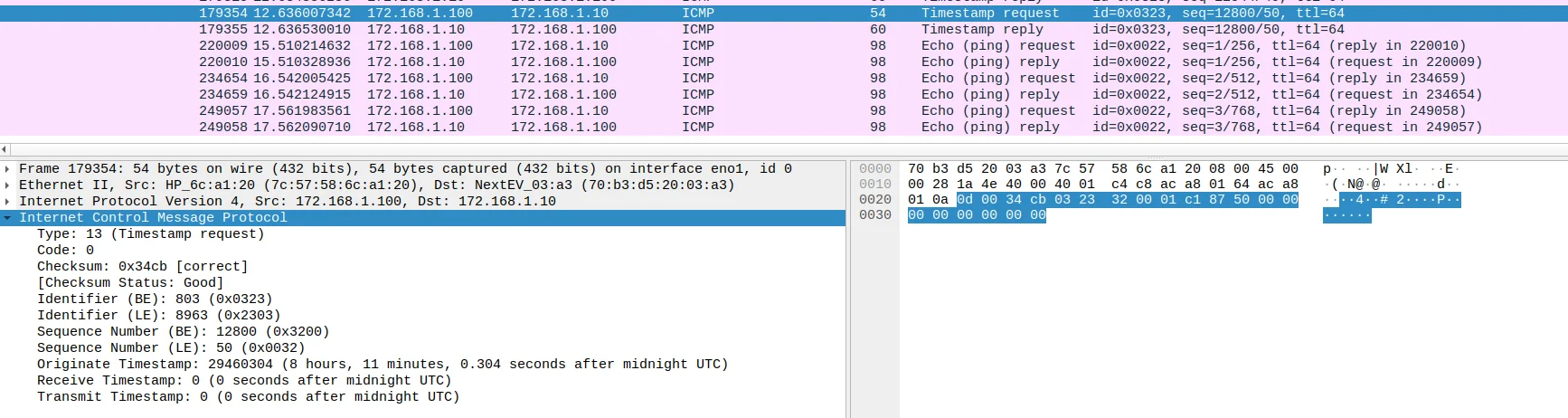
通过wireshark抓包,可以看到在ping命令和clockdiff命令下,ICMP报文的Type和Code字段对应不同的值。
对ICMP Timestamp Request报文,Type和Code分别对应13、0(Reply则是14,0):
timestamp
对ICMP Ping Request(Echo Request)对应的Type和Code分别是8,0(Reply则是0,0):
ping
clockdiff 发送 ICMP timestamp request 先是构造报文的类型:
1
2
3
4
5
6
7
8
9
10
11
mv . length = sizeof ( struct sockaddr_in );
if ( ctl -> ip_opt_len )
oicp -> type = ICMP_ECHO ;
else
oicp -> type = ICMP_TIMESTAMP ;
oicp -> code = 0 ;
oicp -> checksum = 0 ;
oicp -> un . echo . id = ctl -> id ;
(( uint32_t * ) ( oicp + 1 ))[ 0 ] = 0 ;
(( uint32_t * ) ( oicp + 1 ))[ 1 ] = 0 ;
(( uint32_t * ) ( oicp + 1 ))[ 2 ] = 0 ;
ICMP_ECHO先跳过,现在往ICMP报文塞了type = ICMP_TIMESTAMP(13)和 code = 0。这是一个ICMP Timestamp Request报文。
这里的0、1、2三个uint32_t则是ICMP Timestamp报文需求的三个时间戳:发送时间戳、接收时间戳、回传时间戳。这部分是不包含在icmphdr定义中的,所以预分配空间时需要考虑这部分空间。
而后,更新发送时间戳,和checksum:
1
2
3
4
5
6
7
8
9
10
oicp -> un . echo . sequence = ++ ctl -> seqno ;
oicp -> checksum = 0 ;
clock_gettime ( CLOCK_REALTIME , & mv . ts1 );
* ( uint32_t * ) ( oicp + 1 ) =
htonl (( mv . ts1 . tv_sec % ( 24 * 60 * 60 )) * 1000 + mv . ts1 . tv_nsec / 1000000 );
oicp -> checksum = in_cksum (( unsigned short * ) oicp , sizeof ( * oicp ) + 12 );
mv . count = sendto ( ctl -> sock_raw , ( char * ) opacket , sizeof ( * oicp ) + 12 , 0 ,
( struct sockaddr * ) & ctl -> server , sizeof ( struct sockaddr_in ));
这里的发送时间戳使用的是软时钟、系统时间,然后按天取模 ,所以传递出去的时间戳是以当天0点为基准的偏移时间,单位是ms。
时间单位如果用us,则会被uint32_t类型溢出,或者可以考虑使用100us为最小刻度,这样是不溢出的。但是使用非1刻度就需要考虑对端刻度是否一致。
在发送ICMP Timestamp Request报文前,包含一个for循环,这说明需要多次测量,默认是50次:
1
for ( mv . msgcount = 0 ; mv . msgcount < MSGS ;)
clockdiff 接收 ICMP timestamp reply 首先会设置期望的timeout时间:
1
2
3
4
5
6
7
8
9
{
long tmo = MAX ( ctl -> rtt + ctl -> rtt_sigma , 1 );
mv -> tout . tv_sec = tmo / 1000 ;
mv -> tout . tv_nsec = ( tmo - ( tmo / 1000 ) * 1000 ) * 1000000 ;
}
if (( mv -> count = ppoll ( & p , 1 , & mv -> tout , NULL )) <= 0 )
return BREAK ;
如果超时还没收到reply,则认为异常。那么就回到服务端再发送一遍,然后尝试接收。这里的ctl->rtt(默认值1000ms) + ctl->rtt_sigma是动态变化的,主要用于拥塞控制。更新逻辑为:
1
2
ctl->rtt = (ctl->rtt * 3 + diff) / 4;
ctl->rtt_sigma = (ctl->rtt_sigma * 3 + labs(diff - ctl->rtt)) / 4;
这里的diff表示的是,本地发送和接收时间戳的差值,时间戳都来自系统时钟。
上面还没有获取对端的接收时间,获取方式为:
1
2
3
4
5
6
7
8
9
10
if (!ctl->ip_opt_len) {
histime = ntohl(((uint32_t *) (mv->icp + 1))[1]);
/*
* a hosts using a time format different from ms. since midnight
* UT (as per RFC792) should set the high order bit of the 32-bit
* time value it transmits.
*/
if ((histime & 0x80000000) != 0)
return NONSTDTIME;
}
这里只获取对端的接收时间戳,没有获取对端发送时间戳。我认为,一般是没有必要的,如上文,这里的时间戳最小刻度是1ms,一般情况下,接收和发送的时间间隔会小于1ms,是测量不出来的。所以这里没有必要再获取对端的发送时间戳。
而后就是获取两个方向的延迟:本地发送到对端的延迟和对端发送到本地的延迟。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
delta1 = histime - sendtime;
/*
* Handles wrap-around to avoid that around midnight small time
* differences appear enormous. However, the two machine's clocks must
* be within 12 hours from each other.
*/
if (delta1 < BIASN)
delta1 += MODULO;
else if (delta1 > BIASP)
delta1 -= MODULO;
if (ctl->ip_opt_len)
delta2 = recvtime - histime1;
else
delta2 = recvtime - histime;
if (delta2 < BIASN)
delta2 += MODULO;
else if (delta2 > BIASP)
delta2 -= MODULO;
还需要考虑“午夜”问题,因为ICMP Timestamp报文中包含的时间戳是以当天0点起始的。
然后更新最小的延迟:
1
2
3
4
5
6
7
8
9
10
11
12
13
if (delta1 < mv->min1)
mv->min1 = delta1;
if (delta2 < mv->min2)
mv->min2 = delta2;
if (delta1 + delta2 < ctl->min_rtt) {
ctl->min_rtt = delta1 + delta2;
ctl->measure_delta1 = (delta1 - delta2) / 2 + PROCESSING_TIME;
}
if (diff < RANGE) {
mv->min1 = delta1;
mv->min2 = delta2;
return BREAK;
}
这里的RANGE表示最小测量范围,是1ms。
最后测量两设备的时间差是:
1
ctl -> measure_delta = ( mv . min1 - mv . min2 ) / 2 + PROCESSING_TIME ;
PROCESSING_TIME一般是0,这个公式为什么可以表示两设备的时间差?
上述表述中,隐式的假设了本地和对端的时间是同步的,但是一般情况下是存在差异的,先假设本地时间是T,那么对端时间就是T + offset,考虑链路来回延迟都为delay那么,对本地的发送和和对端发送时间T1、T2(对端发送时间等于对端接收时间)有:
1
2
3
4
mv.min1 = (T1 + offset) + delay - T1;
mv.min2 = (T2 - offset) + delay - T2;
==>
offset = (mv.min1 - mv.min2) / 2
这里的基本假设是网络链路来回时延一致。
我想迭代50次的原因之一,也是为了保证来回链路的状态一致,而尽量保证来回时延一致。另外,本地的收发时间戳都是在用户空间获取的软时钟系统时间戳,也有一定的误差(获取时间戳时刻和真实收发时刻的误差),如上公式,只要保证获取发送时间戳和真实发送时刻的差值与真实接收时刻和获取接收时间戳的差值一致(或者差异很小),倒也没有太大影响。
clockdiff 网络异常处理 首先是在发送部分,如果发送的sequence number和接收ack number相差过大,则说明可能丢失报文(链路上丢失,或对端下线):
1
2
3
4
5
6
7
8
/*
* If no answer is received for TRIALS consecutive times, the machine is
* assumed to be down
*/
if ( ctl -> seqno - ctl -> acked > TRIALS ) {
errno = EHOSTDOWN ;
return HOSTDOWN ;
}
然后是在发送时,如果发送失败,则是不可达:
1
2
3
4
if ( mv . count < 0 ) {
errno = EHOSTUNREACH ;
return UNREACHABLE ;
}